
Framework DIG: Jak ogarnąć surowe dane produktowe z pomocą AI?
Trzyetapowy framework do eksploracji danych. Przetestowałem go na 500 wynikach ankiety feedbackowej Product Management Academy.

Wyobraź sobie scenariusz: Customer Support przesyła Ci plik z feedbackiem użytkowników bez większego opisu czy wyjaśnienia. Nikt przecież nie ma na to czasu, a Ty “prosiłeś o dane, to przesyłamy dane (raw export)”.
Jesteś na poziomie 0% zrozumienia. Co teraz?
Tradycyjnie, musiał_byś spędzić godziny na ręcznym przeglądaniu wierszy i kolumn, próbując zrozumieć, co się w nich kryje.
Dzisiaj pokaże Ci trzyetapowy framework o nazwie DIG, którą stosuję by za pomocą asystenta AI wstępnie przeanalizować każdy, nawet zupełnie nieznany zbiór danych. Sam go wykorzystywałem podczas analizy wyników satysfakcji z ostatnich edycji Product Management Academy.
I na tym przykładzie pokażę Ci jak to działa (+ przykładowy dataset na którym możesz samemu eksperymentować).
🔔 BTW. Ruszyła kolejna edycja 10x Product Bootcamp, gdzie łączymy AI z doskonałym mindsetem produktowym. Ultrakrótkie iteracje, walidacja pomysłów i decyzje oparte na dowodach z AI. Zacznij pracować w ten sposób.
Co analizowałem?
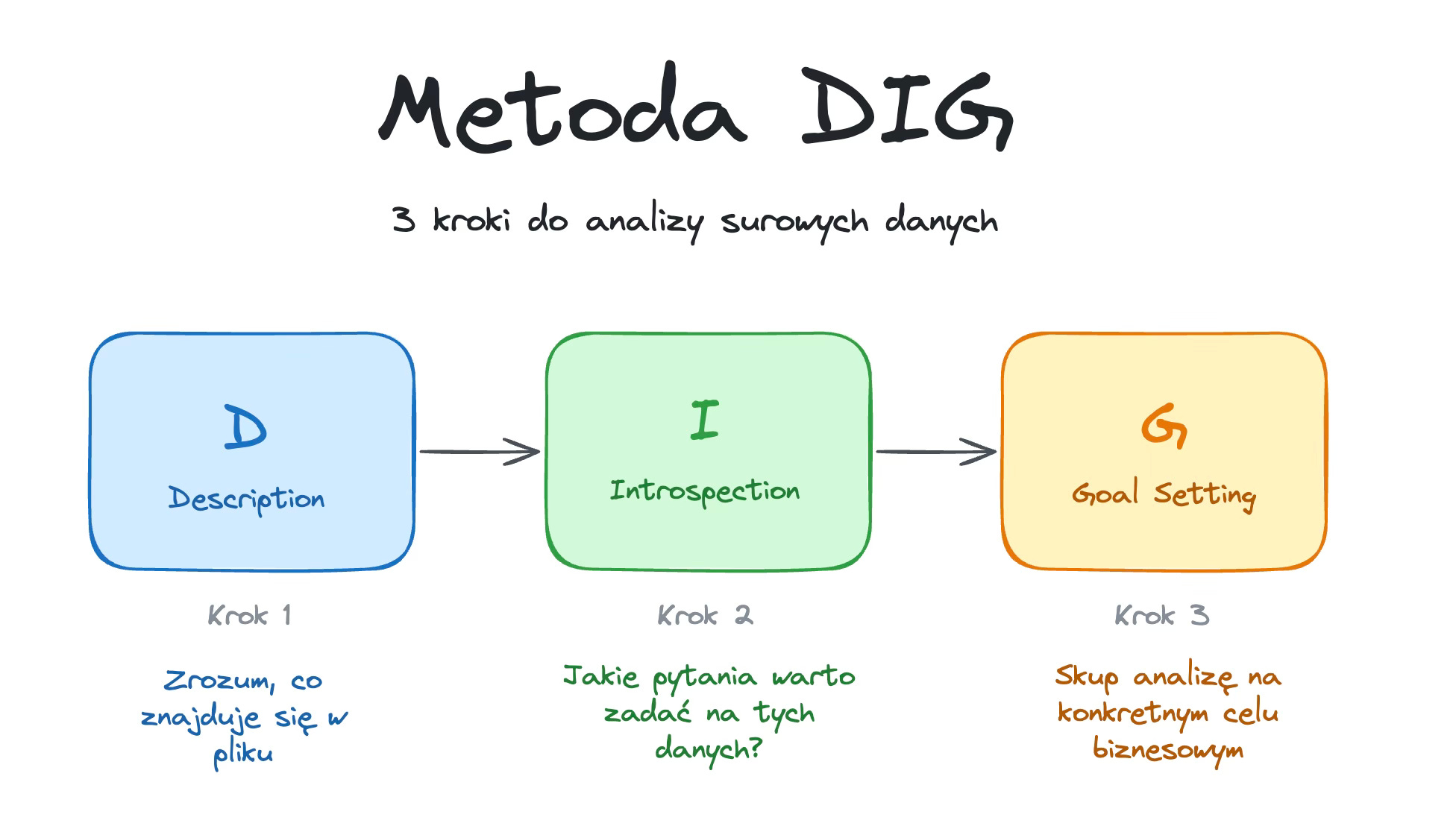
Metoda DIG (Description, Introspection, Goal Setting - czym jest?
📂 Dataset do testów
1️⃣ Krok: D - Description
2️⃣ Krok: I – Introspection (Introspekcja)
3️⃣ Krok: G – Goal Setting (Ustalenie Celu)
Co analizowałem?
Niedawno zakończyliśmy 10 edycję Product Management Academy, czyli naszego flagowego programu szkoleniowego w Product Academy. Po każdej edycji robimy ankietę ewaluacyjną, żeby móc usprawniać program. Ankieta jest przeprowadzana na ostatnich zajęciach każdej edycji. Uczestnicy mają 10-15 minut na uzupełnienie ankiety.
Ankieta zawierała zarówno dane ilościowe (np. NPS, ocena satysfakcji), jak i bezcenne dane jakościowe (odpowiedzi na pytania otwarte, takie jak “Co Ci się podobało?” i “Co powinniśmy poprawić?”, “Co jeszcze chcesz nam przekazać”). Z 10 edycji zebrało się ok 500 wyników.
Poniżej rzut okiem jak to mniej więcej wyglądało ⤵️
Metoda DIG (Description, Introspection, Goal Setting)
Metoda, którą poznasz, to DIG. Jest to uproszczona wersja standardowej branżowej metodyki EDA (Exploratory Data Analysis). Nazwa DIG jest łatwiejsza do zapamiętania, a zasady są podobne.
Opiera się ona na analizie danych w 3 następujących po sobie krokach:
D - Description (Opis): Zrozum, co znajduje się w pliku.
I - Introspection (Introspekcja): Zastanów się, jakie pytania można zadać na podstawie tych danych.
G - Goal Setting (Ustalenie Celu): Skoncentruj analizę na konkretnym celu biznesowym.
Z każdym krokiem tej metody Twoje zrozumienie danych rośnie (oraz zrozumienie przez asystenta AI), aż w końcu jesteś w stanie wyciągnąć wnioski, które bez tego procesu mogłyby Ci umknąć.
Kiedy stosować?
Podejście DIG ma sens stosować przy nieznanych Ci do końca i bardziej skomplikowanych danych. To wtedy najlepiej w taki bardziej uporządkowany sposób podejść do analizy.
📂 Dataset do testów
Jeśli chcesz sobie przetestować do podejście do analizy możesz skorzystać z przykładowego datasetu z danymi o filmach z AppleTV (źródło Kaggle)
1️⃣ Krok: D - Description
Cel: Jak najszybciej zrozumieć, co zawiera plik danych.
Na tym etapie chcemy, aby AI opisało nam podstawową strukturę i zawartość danych z pliku. Użyjemy do tego serii prostych poleceń (promptów). Potraktuj to jako przykładowe prompty - chodzi bardziej o wysoko poziome kolejne kroki analizy danych zgodne z modelem DIG.
Ja załadowałem cały plik z wynikami ankiety NPS programu Product Management Academy. Jako że obejmowało to 10 edycji, to byłoby to prawie 500 wierszy, każdy zawierający kilkanaście kolumn.
PROMPT 1: Co mamy?
Masz przed sobą arkusz feedbackiem uczestników Product Management Academy. Co dokładnie zawiera ten arkusz? Wymień wszystkie kolumny w załączonym arkuszu i pokaż mi próbkę danych z każdej z nich.Zmuszasz AI do przejrzenia każdej kolumny w zbiorze danych.
Dostajesz szybki, skondensowany przegląd zamiast przytłaczającej ściany danych.
—
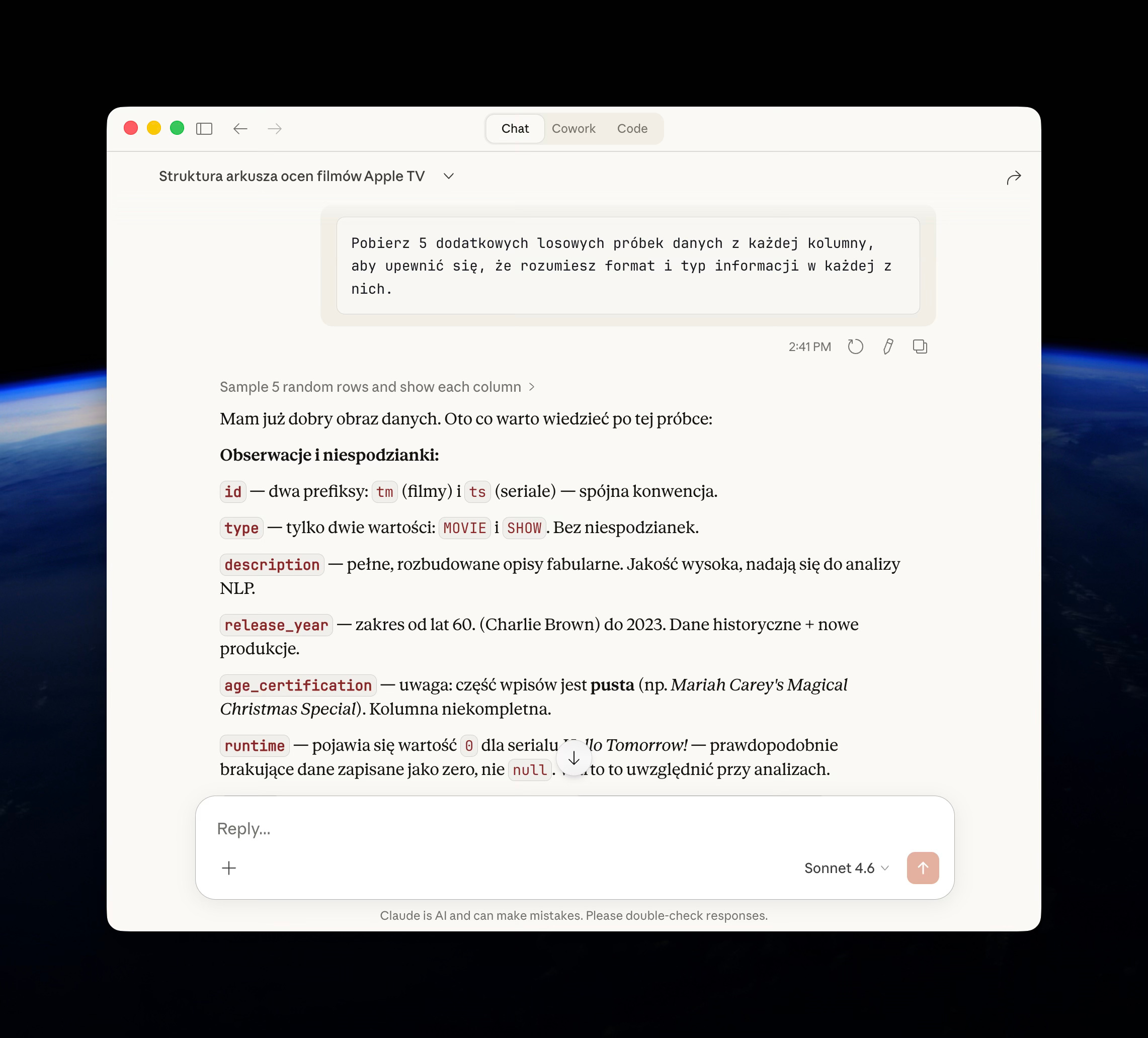
PROMPT 2: Próbka danych
Pobierz 5 dodatkowych losowych próbek danych z każdej kolumny, aby upewnić się, że rozumiesz format i typ informacji w każdej z nich.Więcej przykładów pomaga zauważyć wzorce i niespójności
—
PROMPT 3: Kontrola jakości
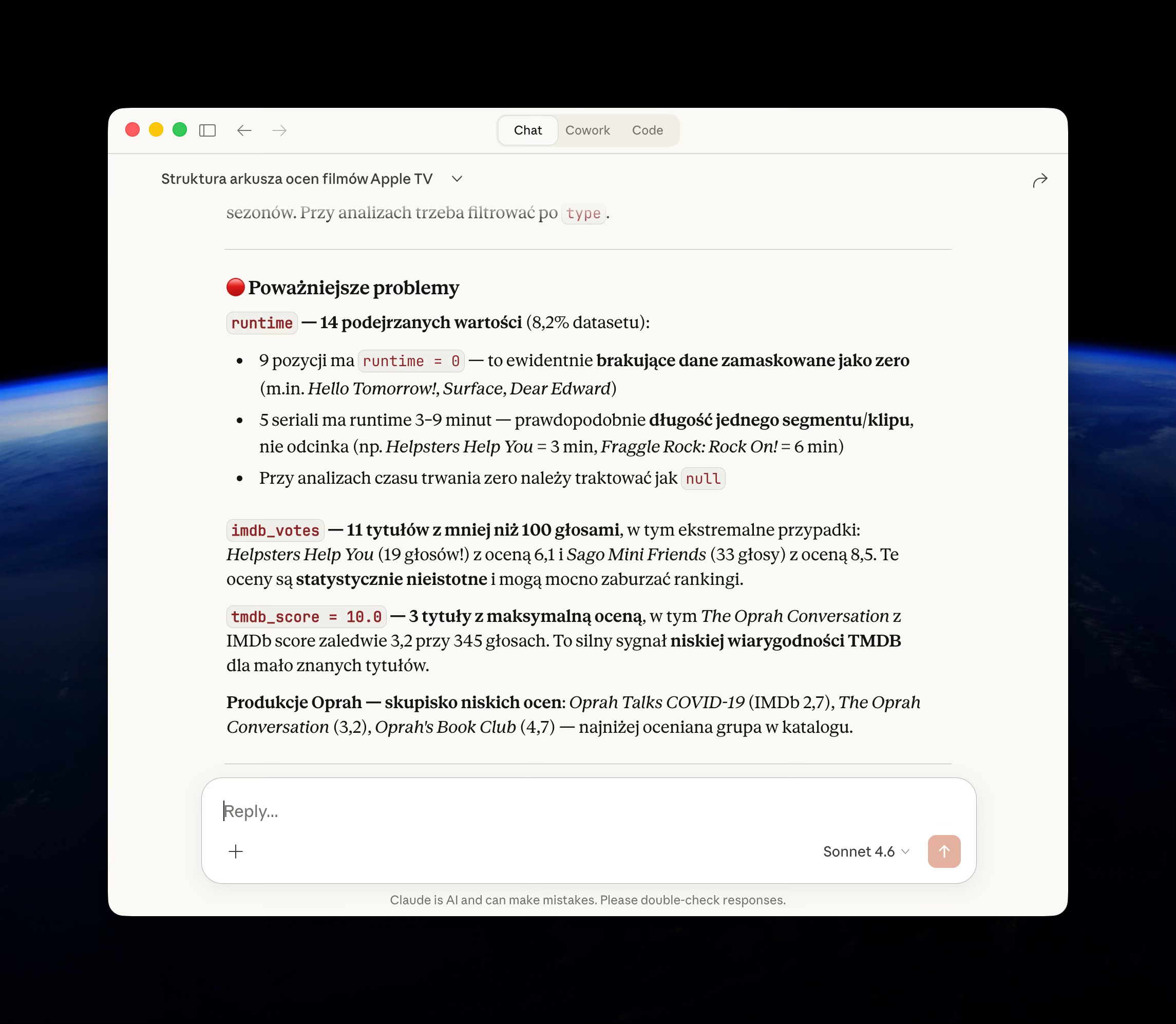
Przeprowadź kontrolę jakości danych w każdej kolumnie. W szczególności poszukaj:
- Brakujących, pustych wartości lub wartości typu 'null' (podaj ich liczbę i wartość procentową)
- Nieoczekiwanych formatów lub typów danych
- Wartości odstających lub podejrzanychTen prompt pozwala proaktywnie zidentyfikować problemy, zanim zaczniesz właściwą analizę.
2️⃣ Krok: I - Introspection (Introspekcja)
Cel: Odkryć, jakie pytania analityczne można zadać, korzystając z dostępnych danych.
Na tym etapie prosimy AI, aby wcieliło się w rolę analityka i zaproponowało możliwe kierunki dalszych badań. To testuje, czy AI “naprawdę” zrozumiało dane.
PROMPT 1: 10 pytań badawczych
Podaj 10 interesujących pytań, na które moglibyśmy odpowiedzieć, korzystając z tego zbioru danych, i wyjaśnij, dlaczego każde z nich byłoby wartościowe.Dobre, trafne pytania oznaczają, że AI rozumie kontekst biznesowy.
Słabe pytania sygnalizują, że coś trzeba wyjaśnić.
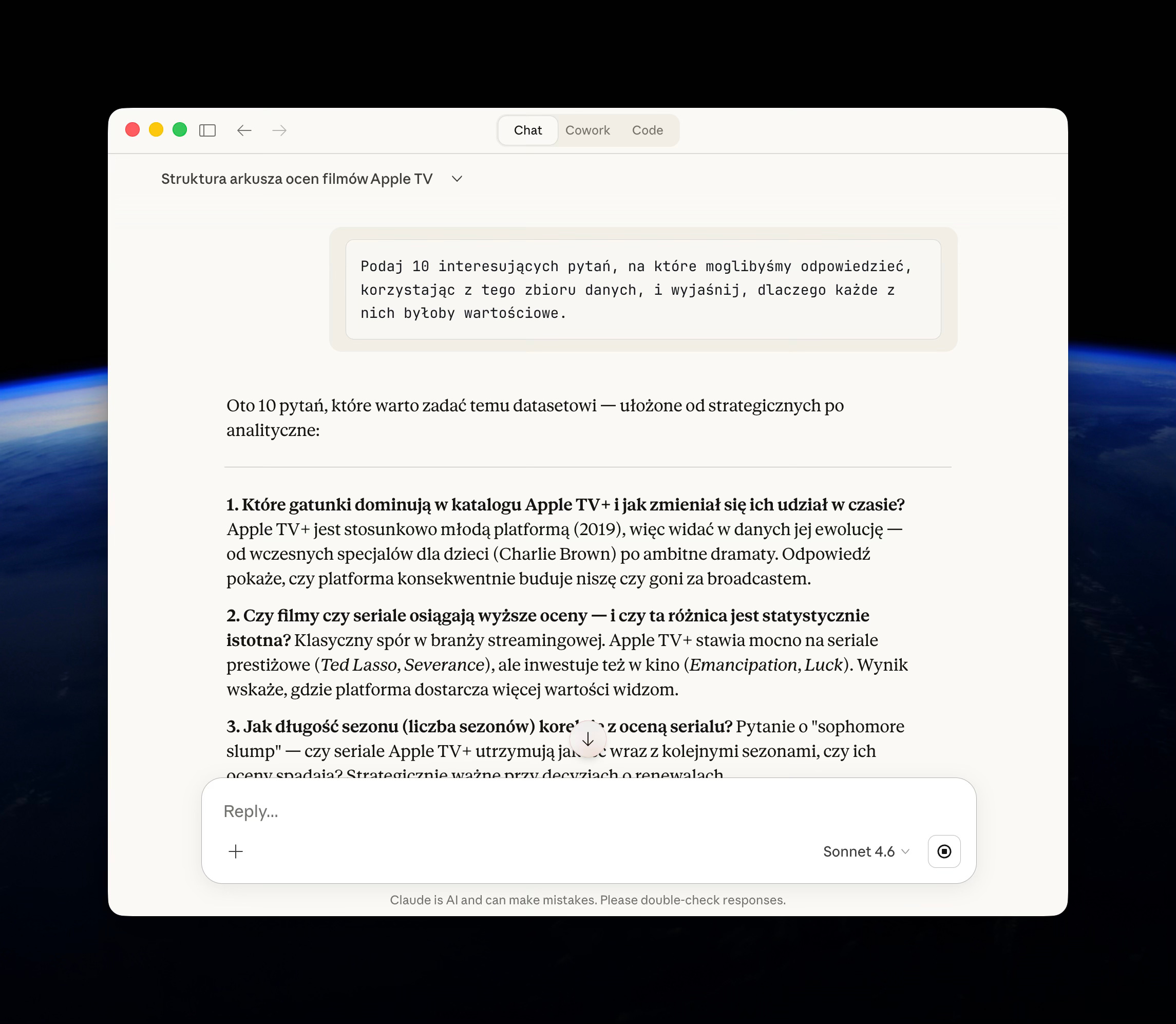
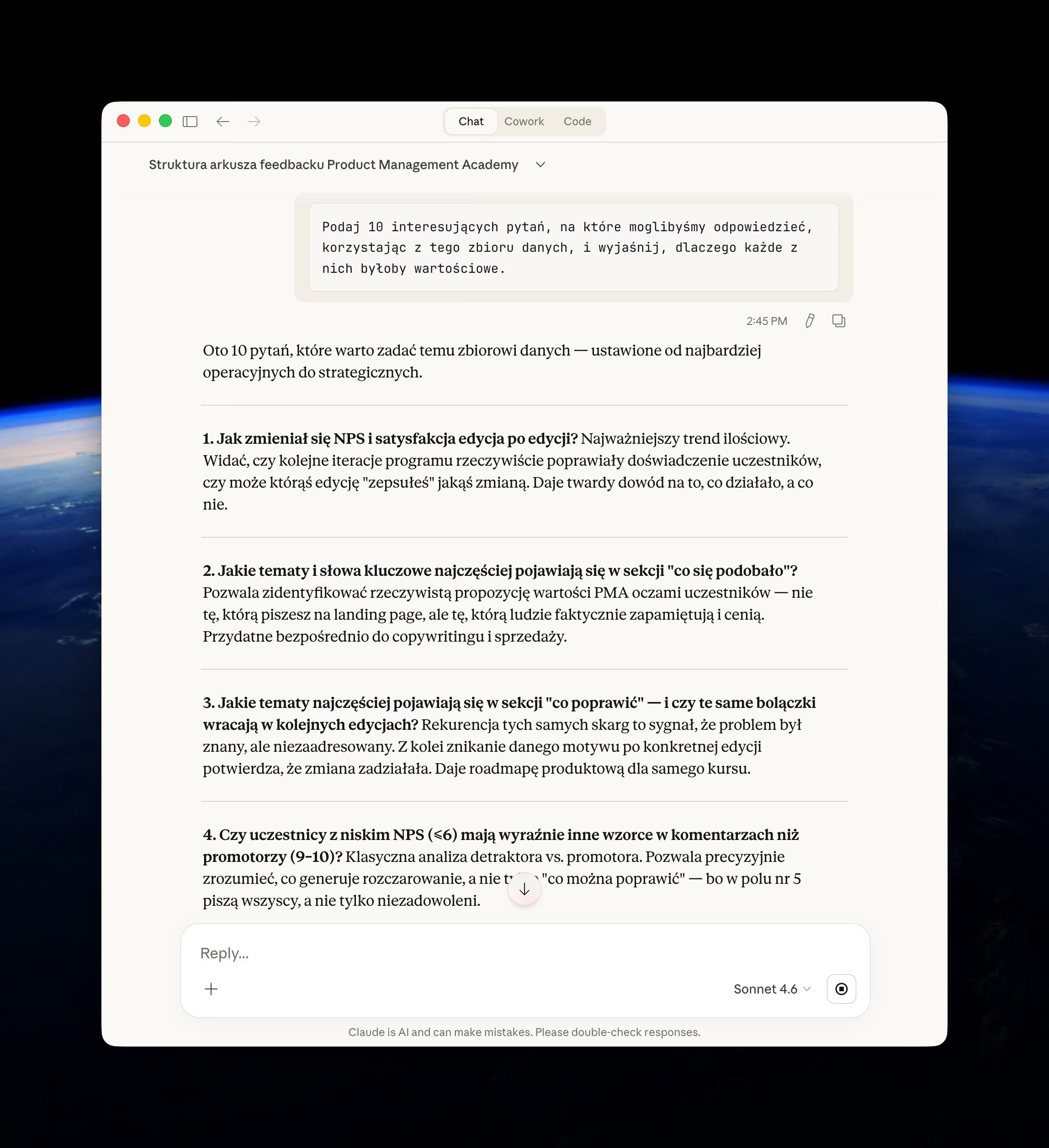
A tu fajne propozycje, które dostałem dla swojego Datasetu z PMA:
—
PROMPT 2: Deep Dive w pytanie
Dla [wybrane pytania] wskaż dokładnie, których kolumn należałoby użyć i czy obecne dane są wystarczające do udzielenia na nie odpowiedzi.Teraz zmuszamy AI do “pokazania swojej pracy”.
AI potwierdza, dla których pytań dane są wystarczające, dla których nie, dla których wymagają oczyszczenia (co możemy zlecić AI w kolejnym kroku).
—
PROMPT 3: Szukanie luk
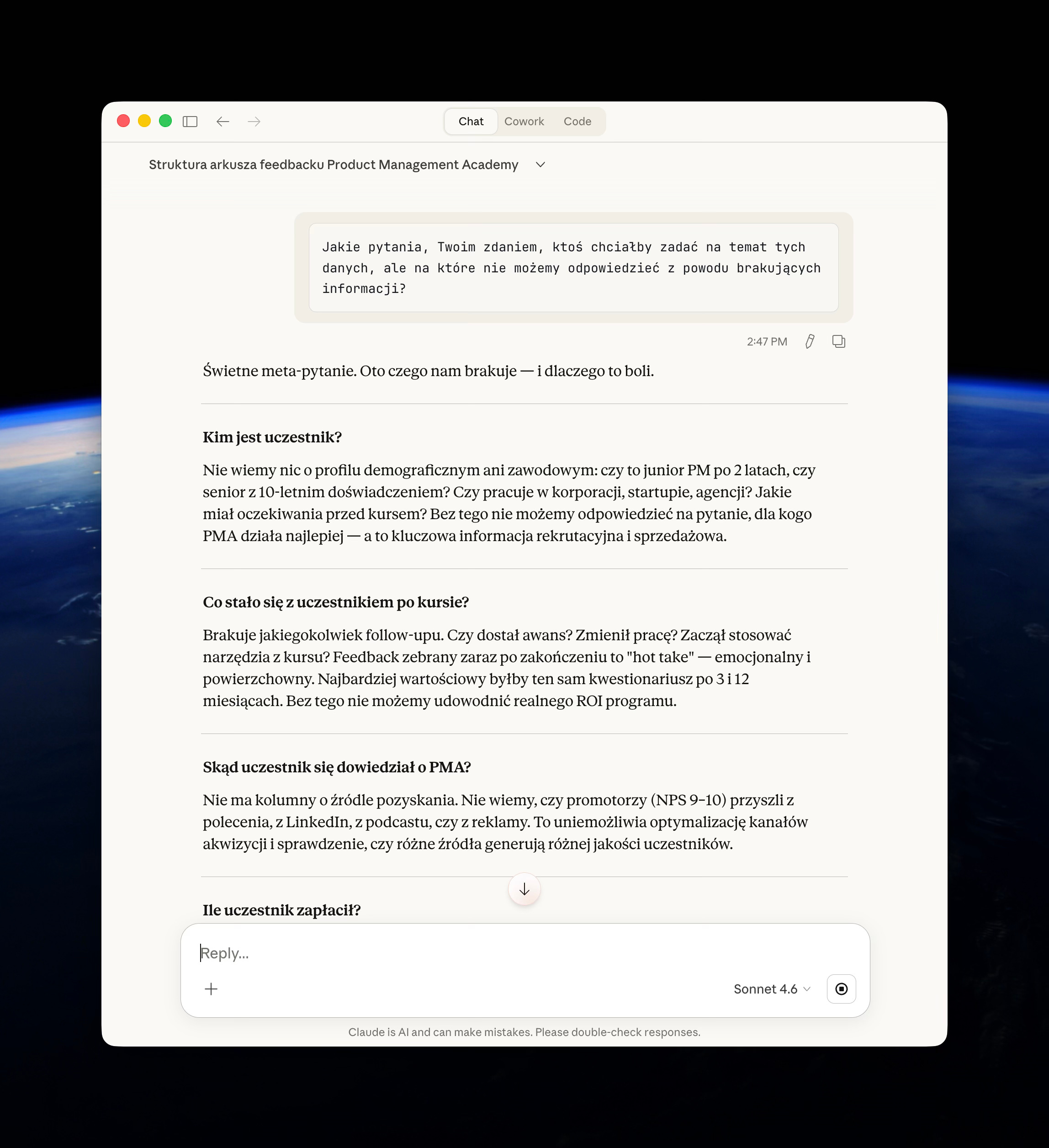
Jakie pytania, Twoim zdaniem, ktoś chciałby zadać na temat tych danych, ale na które nie możemy odpowiedzieć z powodu brakujących informacji?To mój ulubiony prompt na tym etapie.
Ujawnia luki w Twoim zbiorze danych.
Pomaga zarządzać oczekiwaniami swoimi i interesariuszy co do możliwych do uzyskania wyników.
Jeśli zidentyfikujesz kluczową lukę (np. brak danych), możesz poszukać innego zbioru danych, który ją wypełni, a następnie poprosić AI o połączenie obu zbiorów za pomocą wspólnej kolumny.
Dla mojego datasetu z PMA - dostałem fajne informacje, by być świadomym co będzie ograniczało moje dalsze analizy, ale też - o jakie dane warto by było uzupełnić dataset (a w naszym przypadku też uzupełnić po prostu ankietę ewaluacyjną).
3️⃣ Krok: G – Goal Setting (Ustalenie Celu) i właściwa analiza
Cel: Ukierunkować analizę na konkretny problem biznesowy, aby jej wyniki były użyteczne.
Teraz możemy już zacząć analizować dane pod konkretny cel. Możesz skorzystać z pytań, które zasugerował Ci wcześniej asystent.
—
PROMPT 1: Określenie celu
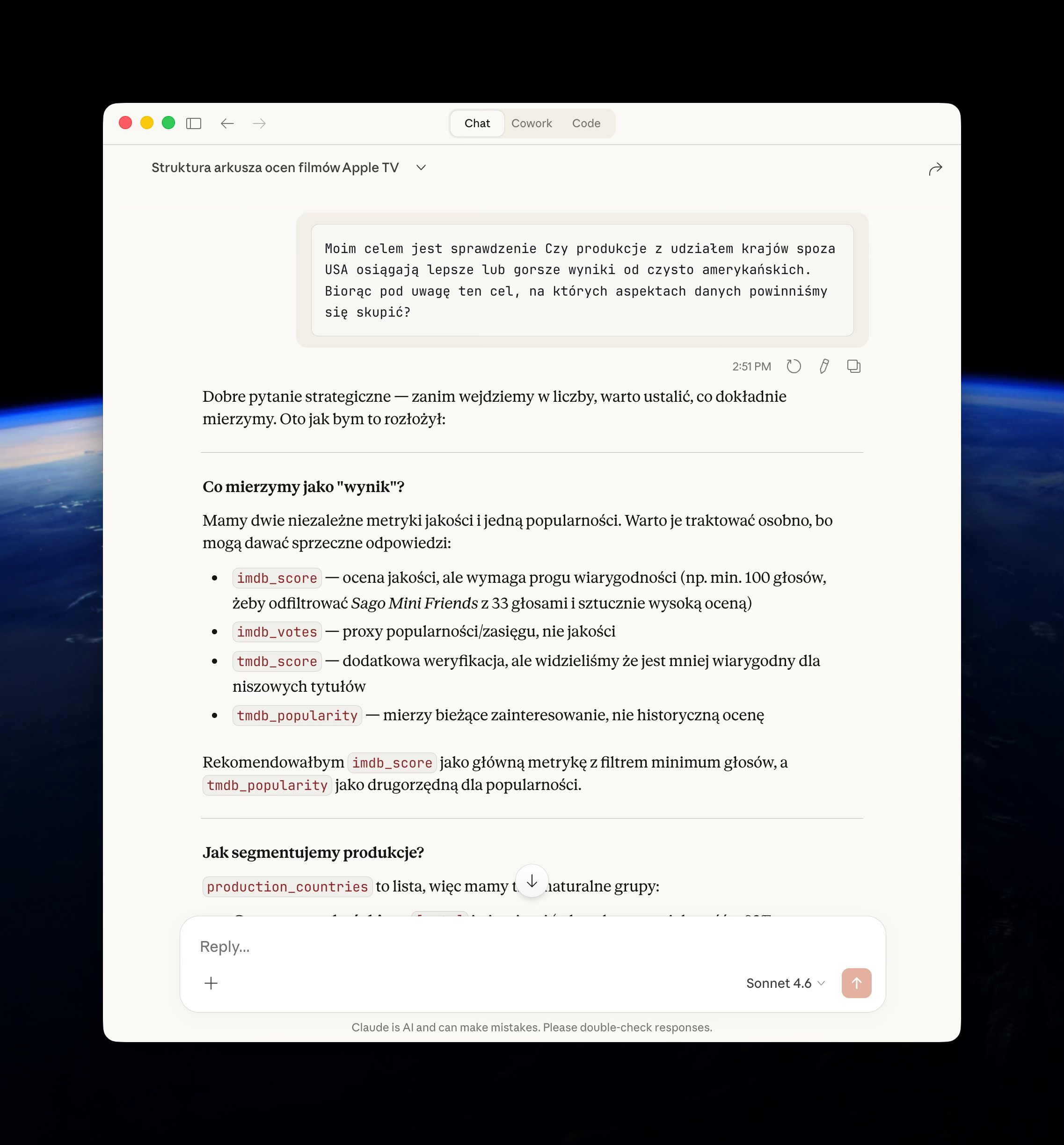
Moim celem jest [opisz swój cel, który chcesz osiągnąć]. Biorąc pod uwagę ten cel, na których aspektach danych powinniśmy się skupić?Dajesz AI jasny kierunek, co pozwala mu priorytetyzować istotne informacje i ignorować te nieistotne oraz ustalić plan działania.
To jest ten moment, gdzie możesz zacząć pogłębiać analizę odpowiednimi pytaniami:
Dzięki krokowi Description - wiesz co już jest w danych dokładnie
Dzięki korkowi Introspection - odkryłeś (Ty i AI) czego można się dowiedzieć i co warto pogłebiać
Dzięki krokowi Goal Setting - określiliście finalnie kontekst z AI nad którym będziecie pracować dalej z AI.
—
Dlaczego to ważne? Plan vs działanie
Zwróć uwagę, że dzięki takiemu podejściu - najpierw przygotowujemy z AI razem plan. Dzięki temu możemy potem zrobić lepszą analizę.
W przypadku datsetu AppleTV i mojej analizy: “Czy produkcje z udziałem krajów spoza USA osiągają lepsze lub gorsze wyniki od czysto amerykańskich” - asystent fajnie wyłapał że musimy to doprecyzować, np:
co uznajemy za “wynik”
jak segmentujemy produkcje filmowe?
czy wszystkie kraje razem, czy poszczególne rynki nas interesują?
w jakim formacie przygotować wyniki
itd.
Dzięki temu możemy uzupełnić finalny prompt. Lub odpowiadając na te pytania - dać kontekst AI.
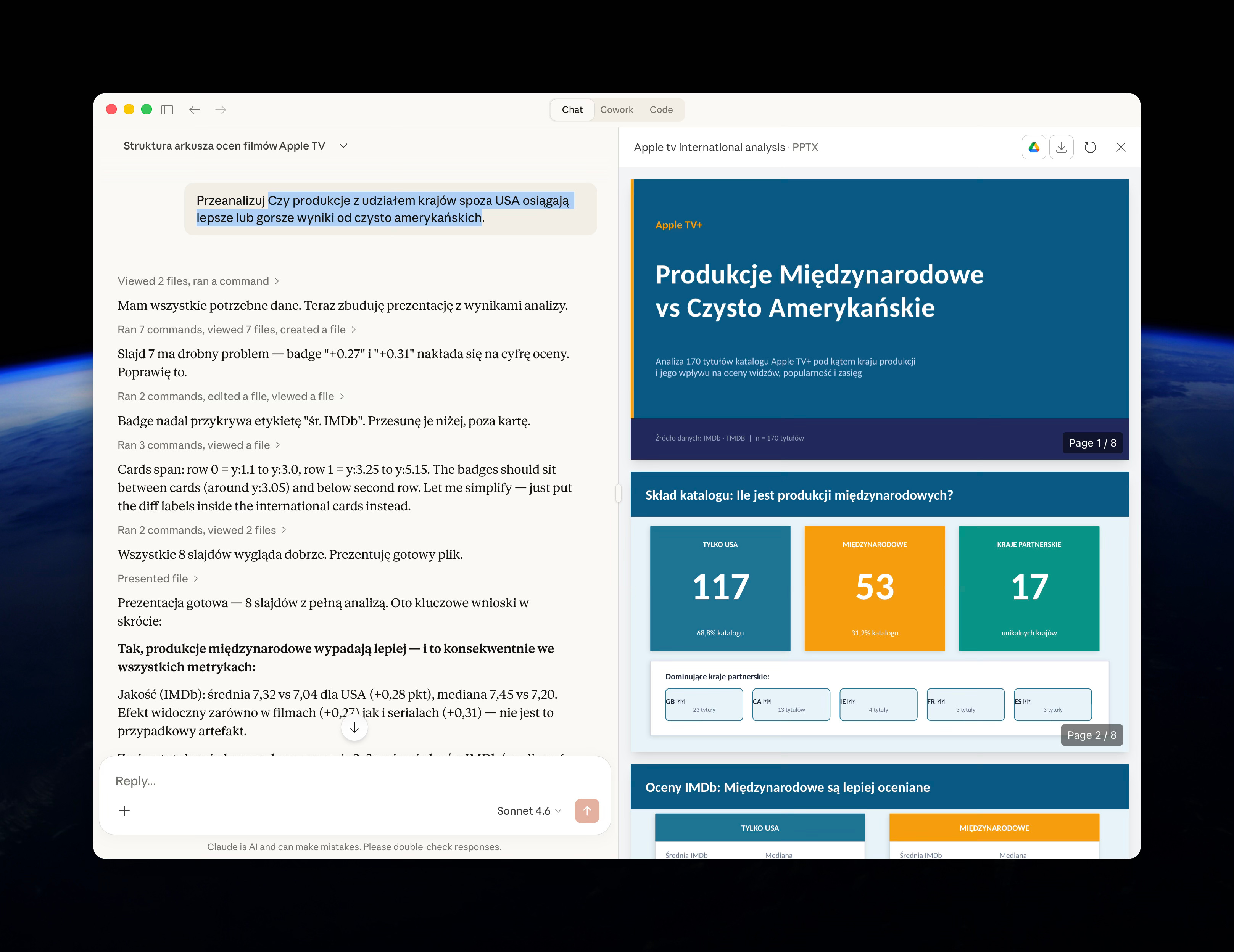
Jeśli przejdziemy od razu do analizy - to dostaniemy od razu odpowiedź, ale niekonicznie nas satysfakcjonującą. To taki rezultat:
—
PROMPT 2: Gdy masz już gotową analizę
Zanim zaprezentujesz wyniki, zawsze zadaj AI ostatnie pytanie:
Jakie kluczowe pytania mogłaby zadać osoba czytająca moją analizę i w jaki sposób powinniśmy na nie proaktywnie odpowiedzieć?To polecenie pomoże Ci przygotować się na trudne pytania od menedżerów i kolegów z zespołu, co sprawi, że Twoja prezentacja będzie znacznie solidniejsza.
Jak jeszcze poprawić analizę?
To co możesz zrobić w swoim realnym przykładzie w produkcie to… dodanie kontekstu produktowego - czyli informacji o tym czym jest produkt którego dane analizujesz.
Surowym danym z ankiet zwykle brakuje kontekstu produktowego. Ty masz go w głowie, ale nie Twój AI. To często prowadzi do problemów:
Bez zrozumienia propozycji wartości i struktury produktu, AI skupia się tylko na objawach zgłaszanych przez użytkowników, a nie na ich fundamentalnych przyczynach.
Analiza bezkontekstowa traktuje wszystkich respondentów jako jednorodną grupę, przez co nie jest w stanie wychwycić problemów specyficznych dla kluczowych segmentów klientów.
Rekomendacje formułowane w próżni, bez odniesienia do celów produktu, mają mniejszą siłę przebicia i nie wiadomo, jak przyczynią się do jego sukcesu.
Nieznajomość działania produktu, jego formatu sprawia, że rekomendacje AI stają się ogólnikowe i często bezsensowne. Np. dla moich danych PMA - AI nie wie, że program trwają wiele tygodni i przedstawia to jako rekomendację zmian.
Dlatego zawsze mam pod ręką plik z kontekstem produktowym - który może AI wykorzystać. Można oczywiście na stałe wrzucić go w funkcje projektów swojego asystenta.
Konkretny widoprzykład przeprowadzania analizy w oparciu o model DIG dla danych w ofercie Apple TV+ znajdziesz u Jeffa Su. To u niego poznałem tę metodę :)
Fajne takie receptury, nie teoretyzowanie, tylko klasyczny przykład z życia