
Dlaczego nie wdrożyliśmy „najlepszego" modelu LLM na rynku?
Jak wybrać model LLM do produktu AI?

„Gemini najlepszy!” „Tylko Claude i Opus!” „GPT-5 wszystko zmienia!”… Każdy, kto buduje produkty z LLM-ami w skali, wie, że takie teksty to bzdura.
Niedawno w zespole podejmowaliśmy decyzję, która dla wielu AI-influencerów krzyczących o „najlepszych modelach” brzmiałaby jak herezja - NIE wybraliśmy najlepszego w benchmarkach modelu AI na rynku.
Dlaczego? Bo prawdziwe pytanie nie brzmi „jaki jest najlepszy model?”. Brzmi: „Jaki jest najlepszy model do NASZYCH zastosowań?” I to jest pytanie, na które powinien odpowiedzieć AI PM.
W dzisiejszym wydaniu:
Dlaczego nie wybraliśmy “najlepszego” modelu?
Dlaczego koszty modeli mają gigantyczny znaczenie?
Jak podejść do wyboru modelu?
Czego unikać - klasyczne pułapki, w które sam wpadałem
Podsumowanie
Ogłoszenia:
W dniach 21-22 maja odbędzie się Product Pro Summit w Sopocie - dwudniowa produktowa unconference, bilety 4 292 zł.
Pozostały ostatnie 2 bilety na naszą wiosenną edycję Product Management Academy - 6 tygodniowy program warsztatów dla PMów (3 239 zł).
1. Dlaczego nie wybraliśmy “najlepszego” modelu?
Kilka tygodni temy decydowaliśmy w produkcie o zmianie głównego wykorzystywanego modelu AI. Mieliśmy konkretny problem z wynikami LLM-a blokujący ekspansję.
Oczywiste rozwiązanie? Upgrade na „najlepszy” model.
Jaki model jest najlepszy? Możemy wejść na LLM Stats albo AI Arena i sprawdzić, który model jest „najlepszy”. Odpowiedź zaczyna się już tu niuansować - to zależy od tego, na który benchmark patrzysz.
GPQA? SWE-bench? MMLU? AIME? Każdy z nich mierzy coś innego.
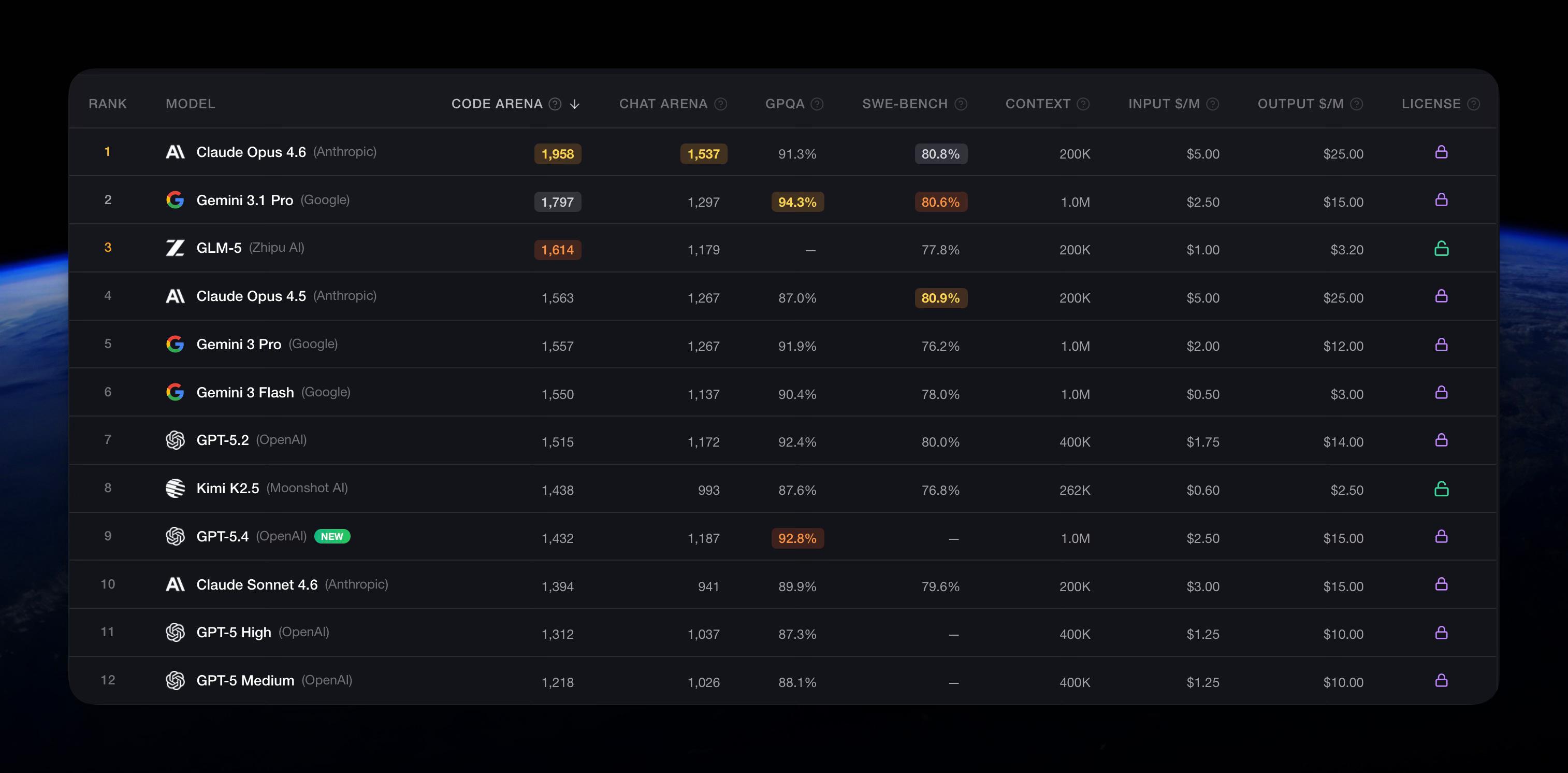
Ale najważniejsze - żaden z nich nie mierzy tego, co naprawdę ważne - jak model radzi sobie z TWOIM konkretnym problemem, na TWOICH danych, w TWOJEJ skali.
Dlatego to co zrobiliśmy to…
1️⃣ Przetestowaliśmy modele na naszych datasetach - nie na abstrakcyjnych metrykach, tylko na danych dotyczących problemu, który faktycznie rozwiązujemy w produkcie. Zmierzyliśmy to, co ma znaczenie dla naszych użytkowników.
Efekt? Zupełnie INNY RANKING niż publiczne leaderboardy. Część modeli z TOP5 globalnych rankingów była u nas daleko w tyle. Modele, które „teoretycznie” powinny dominować, na naszych danych dawały gorsze wyniki niż modele spoza pierwszej dziesiątki.
2️⃣ Policzyliśmy realne koszty — tak, jest model, który daje X% lepsze wyniki... ale kosztuje Y razy więcej. Czy X% poprawa uzasadnia Y-krotny wzrost kosztów?
I właśnie tutaj zaczyna się prawdziwa DECYZJA PRODUKTOWA, nie techniczna:
👉 Atakujemy wyższy rynek z wyższymi marżami, ale musimy szybko walczyć o skalę, żeby to miało sens?
👉 Czy zostajemy na aktualnym rynku, gdzie obecne wyniki są „good enough”, skalujemy go, wiedząc, że wynik produktu będzie trochę gorszy?
Witamy w niedeterministycznym świecie rozwijania produktów AI.
2. Dlaczego koszty mają gigantyczne znaczenie?
Żeby zobaczyć to jeszcze bardziej obrazowo - policzmy koszty dla konkretnego scenariusza - produktu AI z 1 milion generacji LLM miesięcznie (na podobnej skali sam pracuję). Każda generacja to:
5 000 tokenów wejściowych (prompt + kontekst dla LLM-a)
1 000 tokenów wyjściowych (odpowiedź modelu)
To daje nam miesięcznie:
Input: 5 miliardów tokenów (5 000 milionów)
Output: 1 miliard tokenów (1 000 milionów)
A teraz porównajmy dwa przykładowe modele z TOP 10:
Claude Opus 4.6 - najlepszy model w większości benchmarków
Kimi K2.5 - model od firmy Moonshot AI
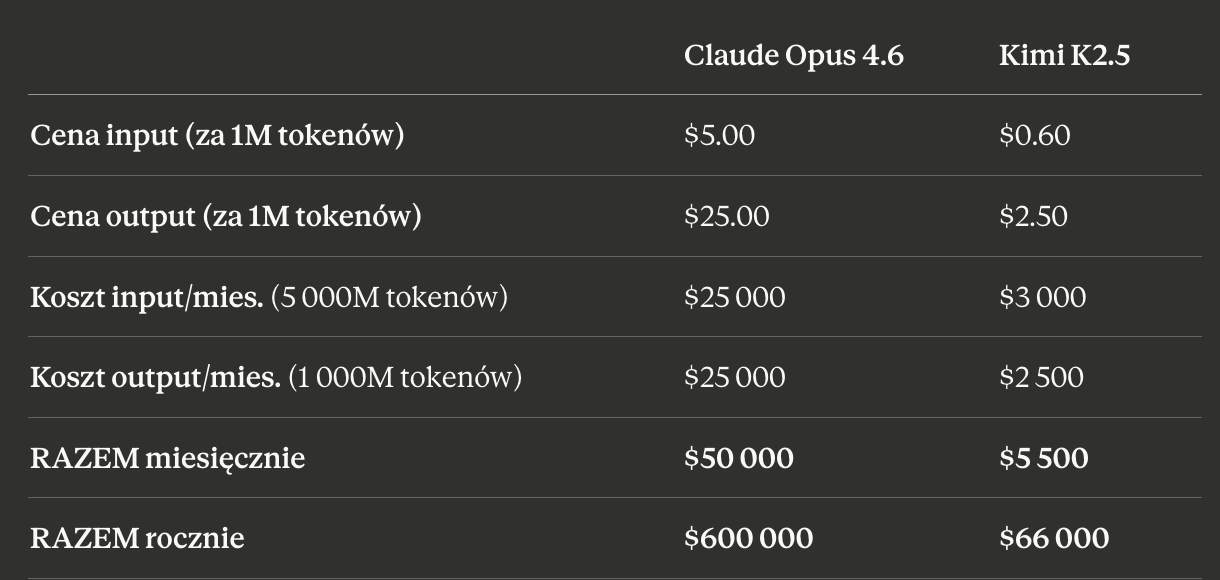
$50 000 vs $5 500 miesięcznie. Prawie 9x różnicy.
$600 000 vs $66 000 rocznie. Za ten sam milion generacji.
I to nie jest porównanie typu „FC Barcelona” vs „Chełmnianka Chełmno” (klub z mojego rodzinnego miasteczka ;). Kimi K2.5 to model z 1 bilionem parametrów, który na wielu benchmarkach niewiele ustępuje popularnym modelom:
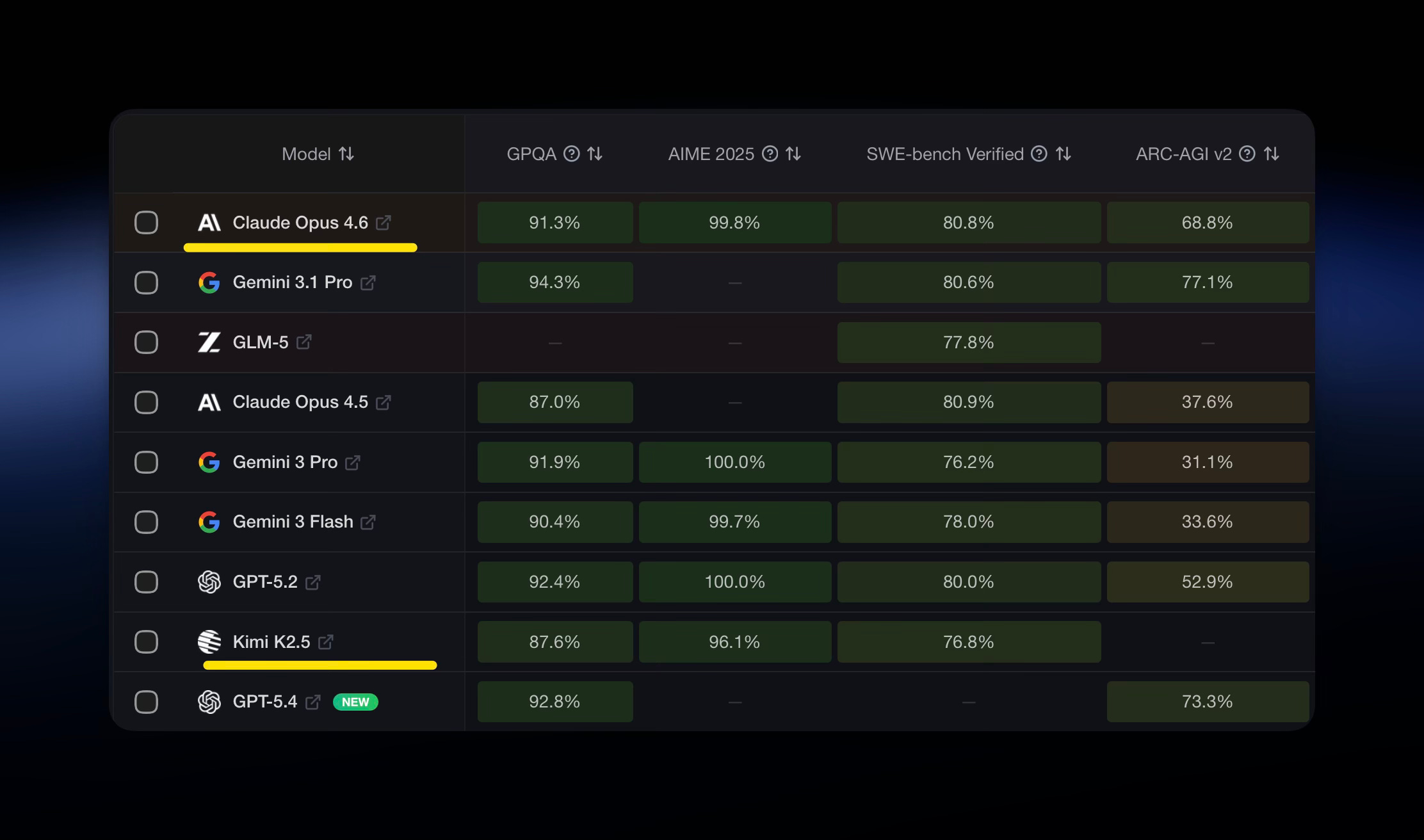
Oczywiście - Claude Opus 4.6 to świetny model. Na wielu zadaniach da lepsze wyniki o kilka %. Ale pytanie nie brzmi „który jest lepszy?”, tylko:
Czy różnica w jakości modeli uzasadnia 9-krotny wzrost kosztów w kontekście TWOJEGO produktu (Twoich danych) i TWOJEGO rynku?
Czasem tak, ale bardzo często odpowiedź będzie negatywna. Dlatego tak ważne jest dobranie modelu do konkretnych zastosowań.
Oczywiście takie obliczenia to uproszczenie - trzeba wziąć pod uwagę choćby kwestię cachowanie promptów. Dlatego tak ważne jest testowanie na swoich danych + przygotowanie takiej analizy z/przez DEV / AI Lead-a.
3. Jak podejść do wyboru modelu?
Na bazie naszych doświadczeń - oto jak podchodzę do wyboru modelu LLM w produkcie. Nie jest to rocket science, ale zdziwisz się, ile zespołów pomija krok 2 i 3.
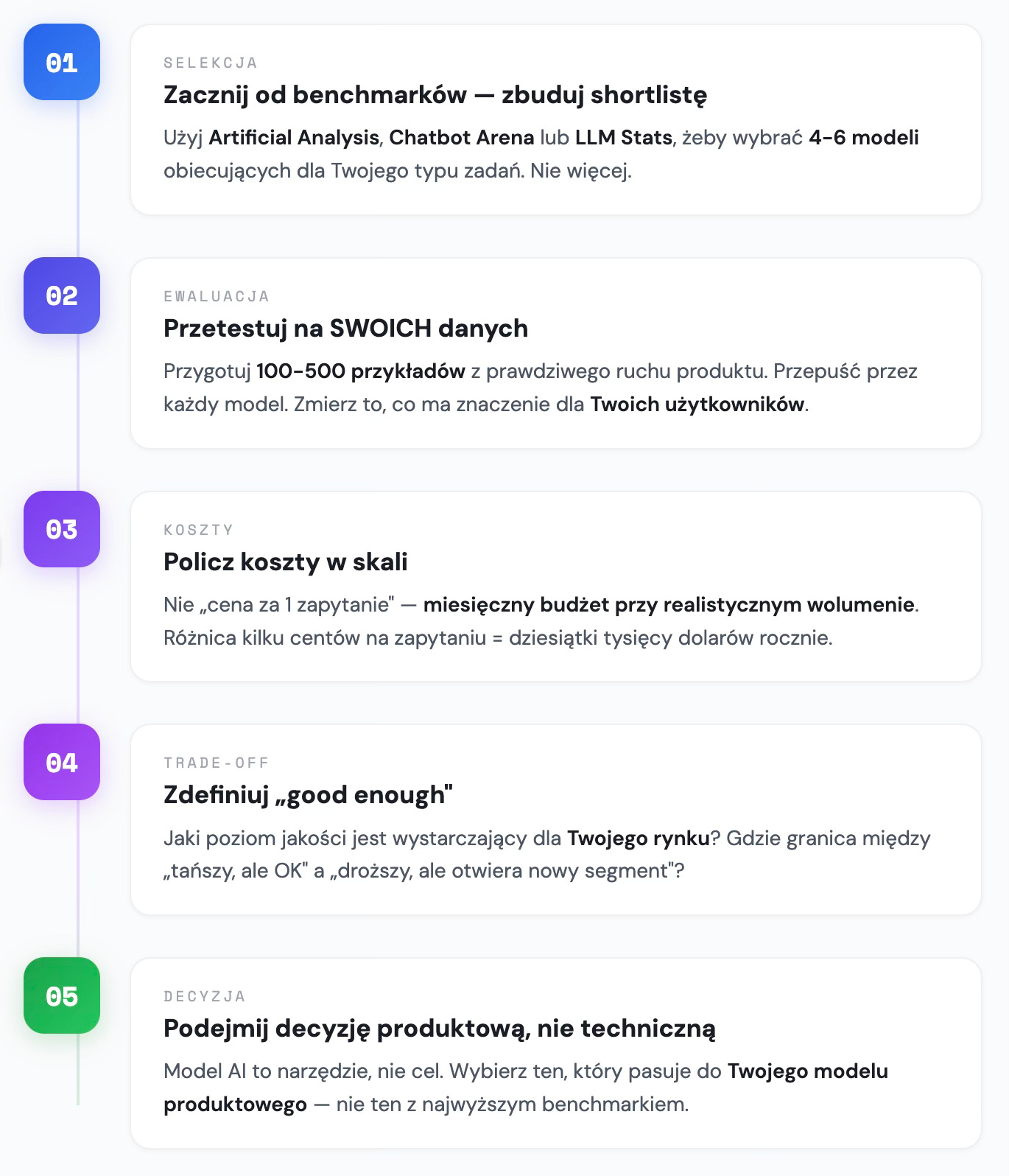
1️⃣ Zacznij od benchmarków
Użyj LLM Stats, Artificial Analysis albo Chatbot Arena, żeby stworzyć shortlistę 4-6 modeli, które wyglądają obiecująco dla Twojego typu zadań.
Nie więcej. To oszczędza czas. Benchmarki służą do wstępnej selekcji, nie do podejmowania decyzji.
-
2️⃣ Przetestuj na SWOICH danych
To kluczowy krok, którego większość PM-ów pomija.
Przygotuj reprezentatywny zestaw przykładów z prawdziwego ruchu Twojego produktu. Przepuść przez każdy model ze shortlisty. Zmierz to, co faktycznie ma znaczenie dla Twoich użytkowników - nie abstrakcyjne metryki.
Jeśli budujesz narzędzie do analizy tekstu - mierz jakość analizy na Twoich tekstach.
Jeśli chatbot - mierz trafność odpowiedzi na pytania, które zadają Twoi użytkownicy.
Jeśli generujesz raporty - oceń jakość raportów na Twoich danych.
I tak, to wymaga pracy. Ale to jest dokładnie ta praca, która odróżnia produkty AI, które działają, od tych, które „powinny działać”.
-
3️⃣ Policz koszty w skali
Nie w „cenie za 1 zapytanie”, ale w miesięcznym budżecie przy realistycznym wolumenie.
Różnica kilku centów na zapytaniu staje się różnicą dziesiątek tysięcy dolarów rocznie. Tak jak policzyliśmy powyżej - $50 000 vs $5 500 miesięcznie to nie jest detal, tylko fundament wpływający na opłacalność Twojego modelu biznesowego.
Weź swój miesięczny wolumen (albo prognozowany), wrzuć do kalkulatora i porównaj realne koszty. Sprawdź kalkulator tokenów na langcopilot.com - uwzględnia caching i Batch API.
-
4️⃣ Zdefiniuj trade-off
Tu wchodzisz w sedno decyzji produktowej:
Jaki poziom jakości jest „good enough” dla Twojego rynku?
Gdzie przebiega granica między „tańszy, ale wystarczający” a „droższy, ale otwiera nowy segment”?
Czy Twoi użytkownicy zauważą różnicę 2% w jakości? A 5%?
To jest moment, w którym PM przestaje być „osobą od backlogu” i zaczyna podejmować realne decyzje produktowe w produkcie AI. Wybór modelu AI to nie kwestia techniczna - to decyzja produktowa.
-
5️⃣ Podejmij decyzję produktowa, nie techniczną
Model AI to nie cel. To narzędzie do realizacji strategii produktowej.
Wybierz model, który najlepiej pasuje do Twojego modelu biznesowego, nie ten z najwyższym benchmarkiem. Czasem „gorszy” model jest lepszą decyzją, bo pozwala Ci skalować szybciej, daje wyższe marże, albo po prostu Twoi użytkownicy nie potrzebują dodatkowych 3% jakości.
4. Czego unikać?
Parę klasycznych pułapek, w które sam wpadałem (i tak, mówię z doświadczenia):
--
🔹 „Ten model jest najlepszy na benchmarkach, więc musi być najlepszy dla nas”
Nie. Benchmarki mierzą coś innego niż Twój produkt. GPQA mierzy wiedzę ogólną, SWE-bench mierzy umiejętność naprawiania bugów w open source. A Ty potrzebujesz modelu, który dobrze analizuje opinie klientów w branży telco po polsku. To nie jest to samo. Zawsze testuj na swoich danych.
--
🔹 „Zmienimy model - to jest proste”
Każdy model ma inną charakterystykę. Twoje prompty, ewaluacje, esse case’y będą od tego zależy. Inny model inaczej reaguje na te same instrukcje. Inaczej się „myli”. Inaczej formatuje output.
--
🔹 „Weźmiemy najdroższy, bo na pewno jest najlepszy”
Widziałeś tabelkę powyżej. 9x w cenie ≠ 9x w jakości. Na naszych danych różnica w jakości między najdroższym a najtańszym modelem na shortliście wynosiła kilka procent, a różnica w kosztach - rząd wielkości.
--
🔹 Ignorowanie kosztów cachingu
Zarówno Anthropic (prompt caching z 90% zniżką na powtarzalne prompty), jak i Kimi (automatyczny cache z 75% oszczędnością) oferują mechanizmy, które mogą drastycznie obniżyć rachunki. Jeśli Twoje zapytania mają powtarzalny system prompt (a pewnie mają), to musisz to policzyć. Różnica bywa ogromna.
5. Podsumowanie
Nie ma „najlepszego modelu”. Jest model najlepszy dla Twojego produktu, Twoich użytkowników i Twojego modelu biznesowego.
Trzy rzeczy, które możesz zrobić po przeczytaniu tego newslettera:
✅ Zbuduj własny eval dataset - zbierz realne przykłady z Twojego produktu i przetestuj na nich 3-5 modeli. Nie polegaj tylko na publicznych rankingach. To jest najprostszy sposób, żeby uniknąć złej decyzji.
✅ Policz koszty w skali - weź swój miesięczny wolumen (albo prognozowany), wrzuć go do kalkulatora i porównaj realne koszty. Różnica Cię zaskoczy.
✅ Zamień pytanie techniczne w biznesowe - zamiast „który model jest najlepszy?”, zapytaj „jaki rynek chcemy obsługiwać i jaki trade-off jakość/koszt akceptujemy?”. Odpowiedź na to pytanie powie Ci więcej niż wszystkie benchmarki razem wzięte.
Jak u Was wyglądają temat wyboru modeli AI do produktowych zastosowań?
A teraz tylko pozostaje się zastanowić, który model wybrać do porównania modeli 😜